For å vite hvordan man skal håndtere dynamiske URL-er er det essensielt at man vet hva det er, og hvorfor du bør håndtere det på en korrekt måte. Forstår man ikke dette, eller ignorer det bevisst eller ubevisst er sjansen stor for at deres potensiale aldri vil bli nådd. Med feil håndtering i ettertid risikerer du også at konverteringskurven blir negativ, selv om du prøver å rette opp i tidligere feil.
Hva er dynamiske URL-er?
Dynamiske URL-er oppstår når nettsider opprettes basert på en brukerhandling. For eksempel ved sortering, filtrering, fasetter, etc. Dette er spesielt vanlig i nettbutikker på kategori-og produktsider, men også på andre typer nettsider med tracking, oversetting og interne søk, etc.
Dynamiske URL-er kjennetegnes ved at URL-strengen forlenges med tegn bak et spørsmålstegn som noen ganger virker logisk for brukere, mens andre ganger ikke.
En eksempel-URL med parameter for sortering på populære produkter kan være:

Hvor vi ser at popular_desc blir lagt til URL-en i en query string (?q=). Dette forstår vi som kode for at siden sorteres på populæritet-synkende. Altså fra populære til mindre populære produkter. Denne URL-en har en enkel tilleggsinformasjon i adressen, men legger vi til flere valg kan den raskt begynne å se rotete og uforståelig ut.
For eksempel slik:

Denne URL-en viser en side med barnesykler. Her kunne vi hentet ut et mye større potensial ved å skille ut med kategori og underkategori slik:

Foruten uforståelige, ulogiske addresser, er dynamiske URL-er kilder til duplikate og nesten-duplikate sider.
La meg forklare:
Duplikat innhold – eksempel
Ser vi det i forbindelse med en nettbutikk kan vi tenke oss en kategoriside liggende i en logisk strukturert adresse som denne:
https://www.nettbutikk.no/gaming/playstation-konsoller/
Denne siden vil vise alle Playstationkonsollene nettbutikken har. Adressen er logisk strukturert og lett forståelig for både menneskelige brukere og søkemotorer.
Klikker vi en knapp på denne siden som sorterer på pris – lav til høy slik som i adressefeltene over får vi en slik URL:
https://www.nettbutikk.no/gaming/playstation-konsoller/?q=price-asc
Innholdet på denne siden vil være helt likt den opprinnelige adressen uten URL-parametere. Altså er siden duplikat, bare med en mindre forståelig adresse.
Nesten-duplikat innhold – eksempel
Ser vi derimot på denne adressen:
https://www.nettbutikk.no/gaming/playstation-konsoller/playstation-4-slim/
Ser vi at dette er en produktside for playstation 4 slim. Denne kommer med forskjellige attributer som farge og harddisk-størrelse.
Brukeren ser på siden og ønsker seg den hvite modellen med 512 GB harddisk – klikker på den ønskede modellen, og blir ført til ny side:
https://www.nettbutikk.no/gaming/playstation-konsoller/playstation-4-slim?catId=1029&type=white&size=512gb
Dette er en enkel, kort tilleggsinformasjon, men som vi så i eksemplene med URL-ene så kan disse adressene raskt bli uoversiktlige.
Siden er nesten lik den forrige, det eneste som er endret på siden er gjerne at fargen er hvit, harddisken er på aktuell størrelse og prisen kan være endret. Resten av siden er identisk til siden uten URL-parametere.
Har man mange slike sider kan man ende opp med en stor mengde duplikate sider, hvor verdi blir spredt ukontrollerbart på tvers av sider, og Google kan misforstå hvilken side som er den som bør rangeres.
Nå skjønner vi kanskje hvorfor Google ikke liker dynamiske URL-er med parametere på et generelt grunnlag. Det er derfor viktig å vite hvordan vi håndterer slik addresser.
Farene ved dynamiske URL-er
Lar man URL-er med parametere løpe løpsk uten kontroll vil man stå ovenfor flere konsekvenser som i verste fall kan være kritisk for bedriften:
- duplikate sider,
- sløs av crawl-budget,
- Google får redusert forståelse av kontekst,
- mindre kontroll over hva som havner i søkeresultatene,
- redusert CTR i søkeresultatene når feil side blir rangert,
- redusert verdi på sider man ønsker å rangere.
Kort fortalt: mangel på kontroll er tapt omsetning for virksomheten.
Hvordan håndterer vi dette?
Hvordan man skal håndtere dynamiske URL-er avhenger av flere ting:
- Den tekniske løsningen
- Type nettsted
- Problemstilling
Jeg går gjennom noen vanlige metoder. Noen gode, noen mindre gode.
Robots.txt
En metode mange bruker er å blokkere crawling gjennom robots.txt-filen. Dette er en rask implementering man kan gjøre ved å legge til følgende tekst i filen:
disallow /q=? e.l.
Feilen her mange gjør er at de misforstår robots.txt-filens formål og egenskaper.
Robots.txt skal ikke brukes til å kontrollere indeksering. En slik kommando i denne filen vil ikke stoppe indeksering av nettsider som faller under blokkeringen.
Noen utfordringer ved å velge robots.txt som løsning er:
- Hindrer ikke indeksering
- Googlebot kan riktig nok ikke se innholdet på siden eller følge lenker videre, men vil gjøre seg en formening om hva den «tror» finnes, og allikevel indeksere siden.
Resultatet vil se slik ut:
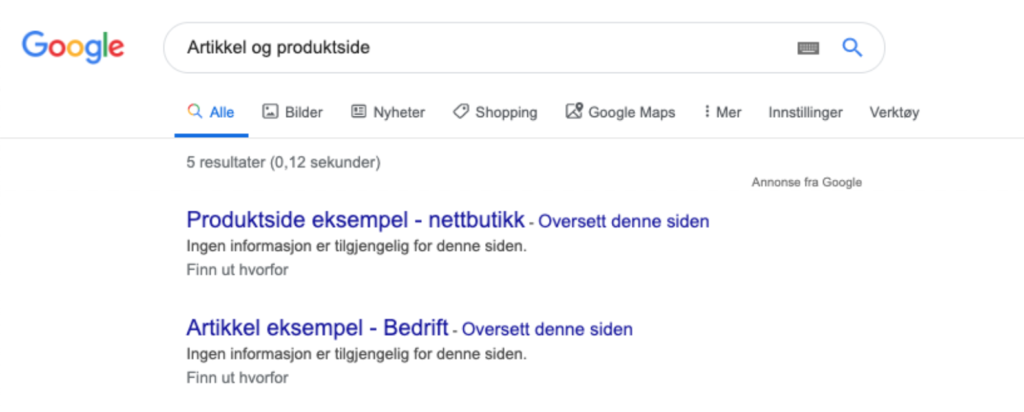
- Googlebot kan riktig nok ikke se innholdet på siden eller følge lenker videre, men vil gjøre seg en formening om hva den «tror» finnes, og allikevel indeksere siden.
- Hindrer deg i å fjerne sider i SERP-en som er satt til noindex
- I og med at Googlebot ikke har tilgang på kildekoden har den heller ikke tilgang på noindex tag-en som gir beskjed om at siden ikke skal være indeksert.
- Hindrer deg i å bygge verdi på nettsider effektivt og optimalt
- Lenker til sider som ikke skal rangeres kan bygge verdi for versjonen som skal rangeres. Blokkerer man gjennom robots.txt er denne potensielle verdien ubrukelig.
Canonical link element
rel=canonical er en tag vi alltid anbefaler kunder å implementere. Canonical tag gir Googlebot beskjed om hvilken versjon som er den originale versjonen du ønsker skal indekseres dersom det finnes duplikate alternativer. Enten om det er på samme domene eller på annet domene.
Canonical tag ser slik ut:
<link rel=»canonical» href=»https://www.domene.no/aktuel-url/»>
Canonical tag bør implementeres på alle nettsidene på nettstedet. Som hovedregel skal denne alltid ha absolutt URL (full adresse med protokoll) og være self-referencing – altså at den skal oppgi seg selv som canonical. Unntaket er der hvor du har en eller flere sider med det samme innholdet. Da skal alle oppgi kun den ene siden du ønsker skal indekseres. Dette er også lurt å tenke på dersom innholdet fra ditt nettsted blir kryss-publisert på andre domener.
Canonical tag er ikke et alternativ for redirects.
I enkelte tilfeller av duplikate versjoner/sider er det mange som bruker canonical tag feil. For eksempel skal det brukes 301-redirect som løsning når man velger hvilken versjon man skal bruke når det kommer til:
- HTTP
- HTTPS
- WWW
- non-WWW
- trailing slash
- non-trailing slash
Men tilbake til temaet..
Når det kommer til dynamiske URL-er bør man implementere en canonical tag utifra hvilken løsning man har og hva man ønsker å oppnå med de forskjellige parameterne.
Gjelder det for eksempel sortering og filtrering bør man alltid oppgi siden uten parametere i URL-en. Da vil Google få beskjed om at det er siden uten parametere du ønsker skal rangere, og alle innkommende signaler til de dynamiske URL-ene skal pekes mot den riktige versjonen.
Tar vi for oss produktvarianter bør man ha en self-referencing canonical tag. Dette gjør det mulig å kunne rangere på flere varianter av samme produkt. Selger man iPhone 11 i seks forskjellige farger, er det ulogisk at alle produktvariantene peker mot kun en variant, for eksempel svart. Da mister man potensielle salg av alle de 5 andre fargene.
Med rel=canonical korrekt implementert, høres dette perfekt ut – men… Canonical tag er ingen kontrollerbar sikkerhet mot å indeksere feil versjon. For Google er canonical tag et «strong hint» som Google ikke nødvendigvis alltid følger. Og jo flere feil et nettsted har med canonical tag – jo større er sjansen for at Googlebot ignorerer dette.
Dersom innholdet på sidene forandrer seg for mye kan også Googlebot konkludere med at dette er to forskjellige sider og indekserer dermed begge. Dette tar fra oss kontroll, og derfor er det ikke den mest optimale løsningen for å hamle opp med dynamiske URL-er.
Bonus: Sørg for at canonical tag ligger i <head>-tag i HTML-dokumentet. Mange velger å legge dette inn i JavaScript. Googlebot vil ikke se taggen før den renderer siden, og når dette skjer har vi ingen kontroll over. Les mer om JavaScript rendering her.
Meta Robots Noindex Tag
Meta Robots Noindex er et direktiv man gir Googlebot. Denne skal ligge i <head>-tag i HTML-dokumentet, og forteller Googlebot at den ikke «får lov» til å indeksere den gjeldende siden. Denne må Google forholde seg til, noe som gjør at vi sitter med kontrollen over hva som havner i søkeresultatsidene.
Noindex tag implementeringen ser slik ut:
<meta name=»robots» content=»noindex,follow»>
Denne vil ikke hindre videre crawling fra og til sider, noe vi heller ikke ønsker at den skal. Dersom noen likevel skulle ønske dette kan man endre den siste kommandoen til nofollow:
<meta name=»robots» content=»noindex,nofollow»>
Dette sørger for at Google ikke følger lenkene på den siden videre.
Merk: Dette endrer seg 1. mars 2020, da vil nofollow kun være ansett som et hint av Google.
Dette er en metode vi i mange tilfeller velger å anbefale for våre kunder, da den er henholdsvis enkel å implementere, og lite utsatt for feil. Den sikrer oss kontroll av hvilke sider Google skal indeksere, og vi kan bygge og optimalisere en sterk sideversjon som vi kan målrette mot kunder og markeder. Dette avhenger dog av at det arbeides flittig og smart med nettstedsstruktur.
Obs; Canonical tag bør ikke kombineres med en noindex tag, da dette vil kunne sende blandede signaler til Googlebot. Googlebot kan tolke det dit hen at canonical tag er feil, og at noindex tag blir overført til den siden du ønsker skal rangere. Altså, side A oppgir seg selv som canonical, og side B oppgir side A som canonical. Side B er satt til noindex. Googlebot misforstår og tror at både side A og B skal være noindex.
Canonical tag bør derfor fjernes fra sider med noindex. Dette fører til at denne metoden ikke vil være den mest effektive for å flytte verdi fra dynamiske sider til den statiske siden du ønsker skal indekseres. Men til gjengjeld vil man være sikker på at man får opp riktig versjon i søkeresultatene, og optimalisere denne slik at CTR øker, og du ender opp med konverteringer og salg.
Bonus: Regelen om å ikke legge tags ment for <head>-tag i HTML-dokumentet i JavaScript fra forrige punkt gjelder også her. Du vil risikere at sider blir indeksert selv om du plasserer en noindex tag i JavaScript.
Nettstedsstruktur
Ukritisk noindex på alle parametere på nettstedet kan være veldig skummelt. Selv om noindex ofte er en god løsning, gjelder denne kun i de tilfeller hvor parametere faktisk gjør den jobben de skal, der hvor struktur på nettstedet ikke er en optimal løsning.
Vi mener at når man utvikler et nettsted er god informasjonsarkitektur og nettstedsstruktur avgjørende for om du lykkes eller ikke, og bør dessuten være noe av det første man ser på når det kommer til utvikling av et nytt eller gammelt nettsted.
Eksempelet under viser hvordan et lite beskrivende parameter har overtatt plassen hvor struktur absolutt burde ha vært tilstede.
Brukeren har en klar kjøpsintensjon, men mangel på målretting gjør at man mister potensielle salg allerede før de kommer inn på nettstedet.
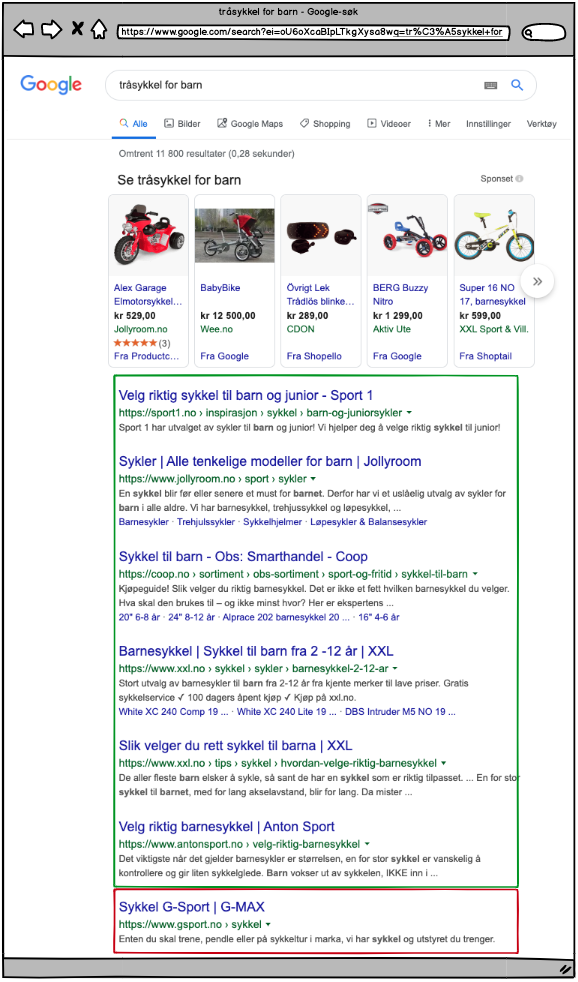
Vi legger merke til hvordan G-Sport rangerer med «Sykkel», der hvor brukeren faktisk har bedt om tråsykkel spesifikt for barn.
Dette vil redusere CTR:
- Ingen hint i tittel om at innholdet på siden er ment for barn
- Ingen hint i URL at siden er ment for barn
- Ingen hint i metabeskrivelsen om at siden omhandler sykler for barn
- Ingen call-to-action I metabeskrivelsen
- Søkeordet er ikke tilstede noe sted
Klikker vi oss videre inn på G-Sport ser vi følgende:
- Vi kommer inn på kategorisiden for alle tråsykler. Brukerene er ikke interessert i alle tråsyklene, de har bedt spesifikt om barnesykler.
- Det kreves 3 ytterligere klikk for å filtrere oss til tråsykler for barn. Tungvindt, tregt og dårlig brukeropplevelse.
- Ikke bare har G-Sport mistet mange kunder allerede i søkeresultatet på Google, men flere vil forsvinne da det er for mange steg før de kommer til ønsket innhold. For kundene tar denne prosessen fire klikk, når de kunne klart seg med ett.
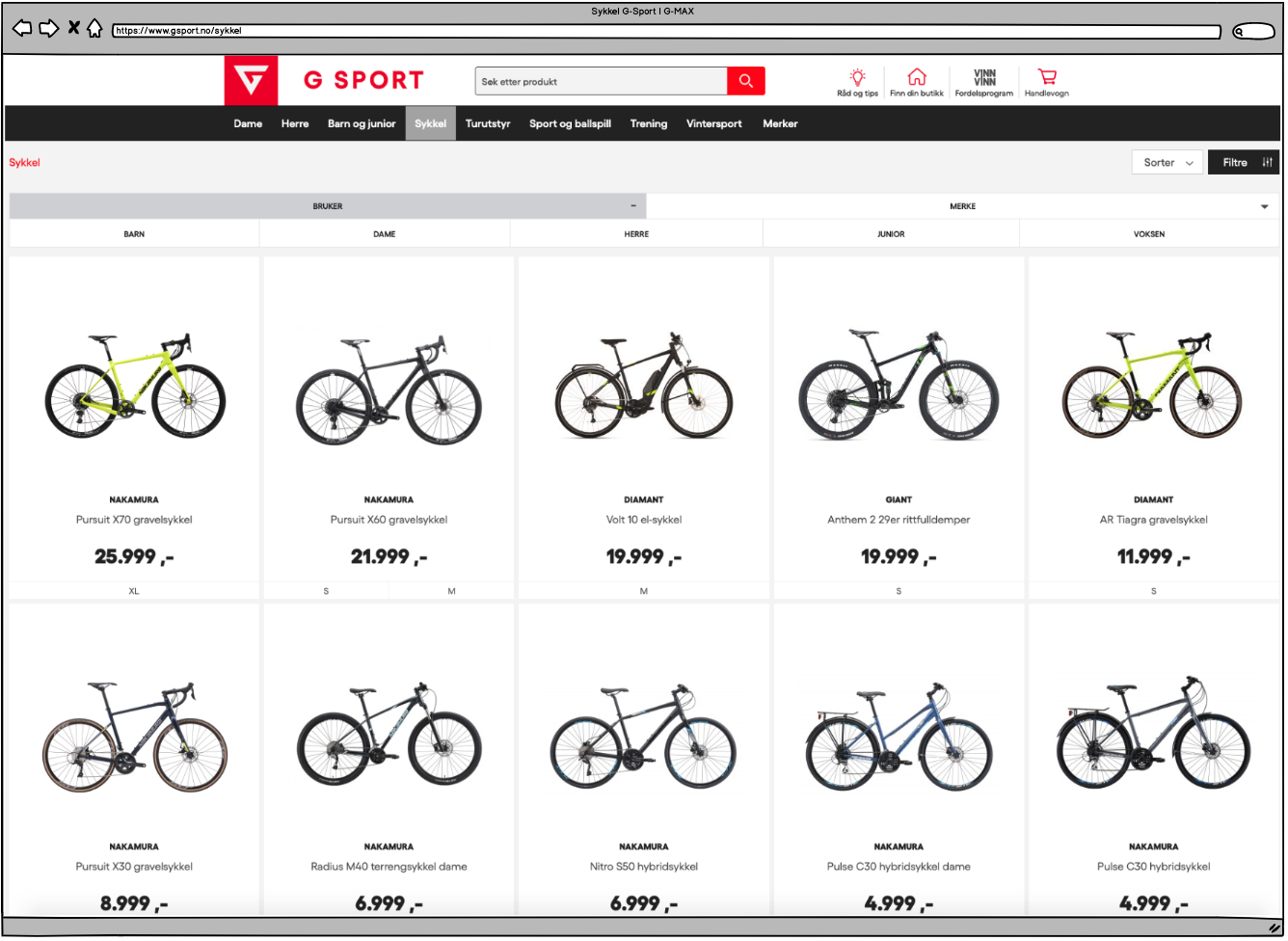
Hvorfor rangerer denne siden når de har en side for barn?
Ta en titt:
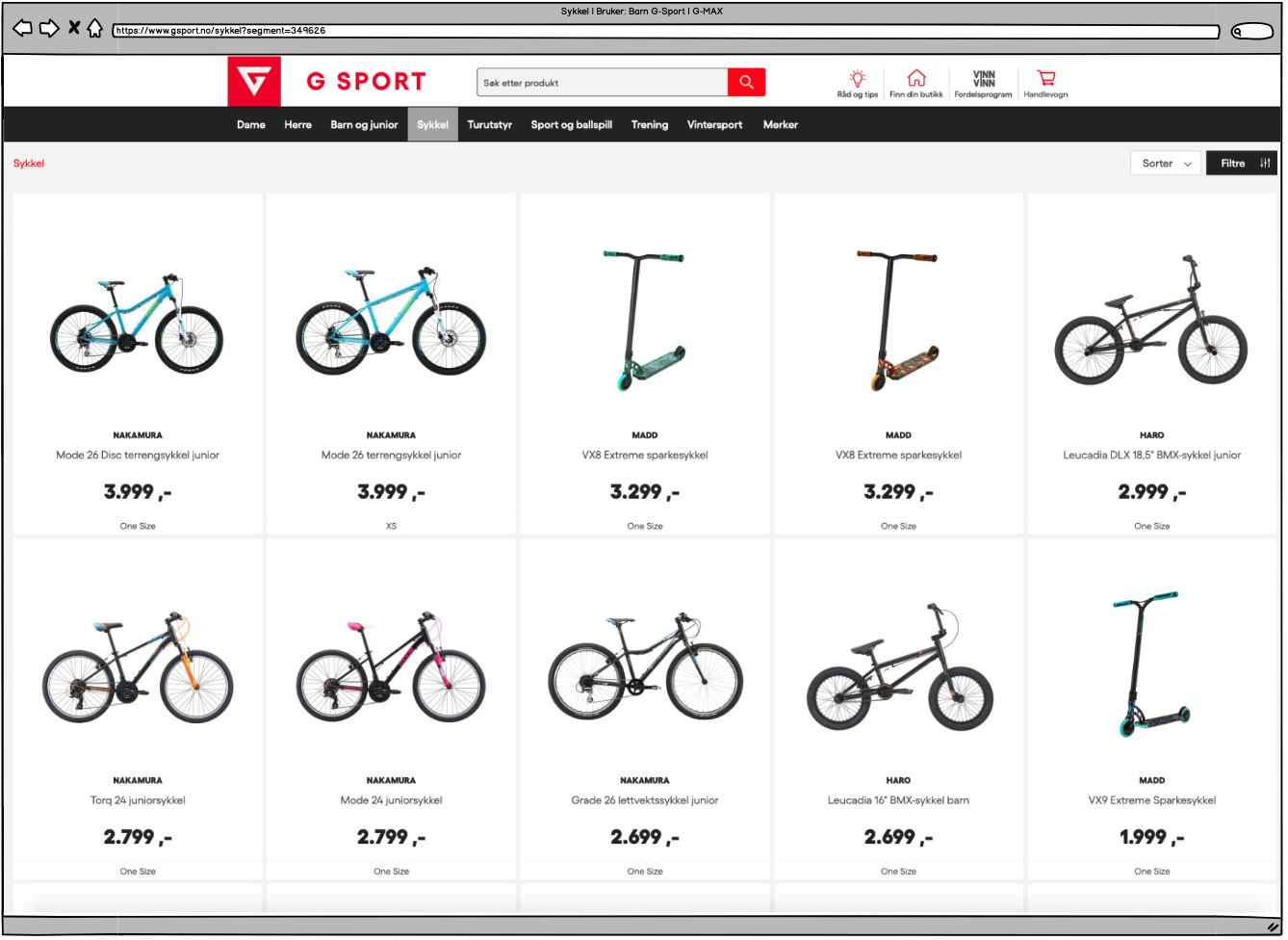
Her ser vi et tilfelle hvor et parameter helt klart ikke er en easy fix for god struktur. Kunder får ikke det de ber om. De må finne frem selv.
Noen punkter å bite seg merke i:
- Parameter i URL-en. «?segment=349626» Hva med denne tilsier at du nå er inne på en side med sykler for barn?
- Heading på siden er følgende: «Sykkel». Hvilket er en duplikat av sykler for barn, damer, menn, voksne, juniorer og alle sykler.
- Alle sykler over folden med unntak av én er sykler for juniorer, ikke barn.
- Ingen egnet målrettet body-tekst på siden.
- Med andre ord, ingenting annet enn tittel på siden gir hint om at denne siden er spesifisert for de som ønsker en tråsykkel til barn.
Se for deg dette scenarioet: Du går inn i en sportsbutikk med ditt barn på 6 år i hånden, spør personalet om å få se utvalget av barnesykler. Responsen du får er «Der borte». Tilhørende er en pekende hånd mot sykkel-avdelingen. Ville du lagt igjen tusenvis av kroner samt et grønt smil på Happy or not meteret?
Ikke det? I rest my case. Det samme gjør Google.
Så, hvordan løser vi dette?
Bedriftens suksess avhenger av at slike viktige avgjørelser ikke blir gjort med en finger i luften. Slike avgjørelse bør baseres på data som støtter oppunder valgene om det bør være parameter, eller om det bør skilles ut i egne kategorier og underkategorier.
For å vite dette må en kjenne sitt marked. En grundig søkeordsanalyse vil komme godt med i dette arbeidet. Men ord og tall alene er ofte ikke nok. Her bør man inkludere en SEO-ekspert tidlig i fasen slik at vi kan være sikre på at de riktige avgjørelsene blir tatt. Feiler man allerede her er sjansen stor for at pengesekken forblir lett.
Google Search Console URL Parameter Tool
Google Search Console tilbyr et verktøy hvor du kan håndtere dine kjente parametere. Her må du gi Google informasjon på hva parameteren gjør/endrer, og hvordan du ønsker Google skal håndtere det.

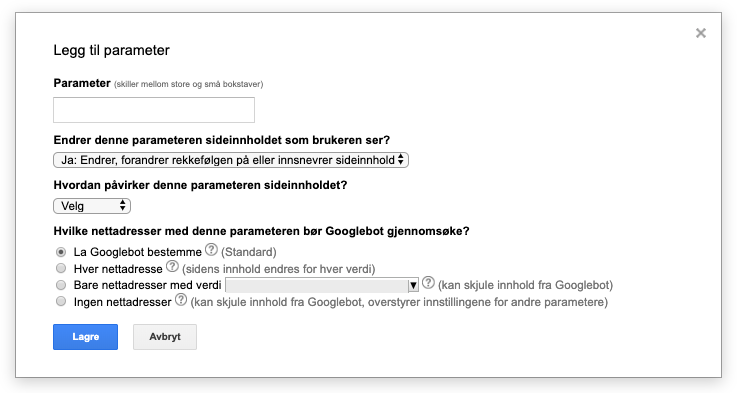
Dette var nok en bedre løsning for de med liten eller ingen teknisk kunnskap tidligere. Endringer du gjør her vil naturlig nok kun gjelde Google, ikke Bing, DuckDuckGo eller andre søkemotorer.
Jeg vil dog ikke gå i dybden på dette verktøyet, da det muligens vil forsvinne eller endres siden det ikke blir direkte flyttet over til den nye Google Search Console-versjonen.
Hva gjør vi med paginering?
Paginering er det vi kaller når vi bryter opp sider over flere URL-er. Gjerne slik: Side 1, side 2, side 3, osv. I bunn av sider som er med i et pagineringssett vil man kunne finne slike lenker:

Her kan man enten bruke dynamiske eller statiske URL-er. I følge Google spiller det ingen rolle for søk, men vi vil allikevel trekke ut noen punkter man skal være obs på når du skal velge en løsning for ditt nettsted.
Ser vi for oss side 2 kan en dynamisk URL for denne siden se slik ut:

Legg her merke til ?page=2 som viser at dette er et parameter. Dette er en svært vanlig måte å løse det på.
Her gir alle nivåer i URL-strukturen verdi for brukerene, og man unngår unødvendige nivåer.
Bruker du dynamiske URL-er må du sørge for at det blir servert en 4xx-side dersom en URL ikke er gyldig. Tester viser at Googlebot kan gjette seg til neste URL dersom den registrerer at det blir brukt dynamiske URL-er til paginering.
Potensielt kan dette skape en spider trap. Googlebot kan gå seg vill i uendelig med sider som egentlig ikke finnes, men de finnes på bakgrunn at Googlebot «oppretter» URL-ene selv. Ikke bare blir dette et stort antall sider med tynt og duplikat innhold, men du sløser bort store mengder crawlcost som kan ha negativ betydning for dine resterende sider og deres bidrag mot virksomhetsmålene.
I tilfellet nedenfor ser vi finn.no med en potensiell spider trap. Selv om det er implementert noindex,nofollow vil ikke Googlebot trenge lenker for å gjette seg til neste side. En 4xx-side vil dermed stoppe en potensiell spider trap på en mer kontrollerbar måte.
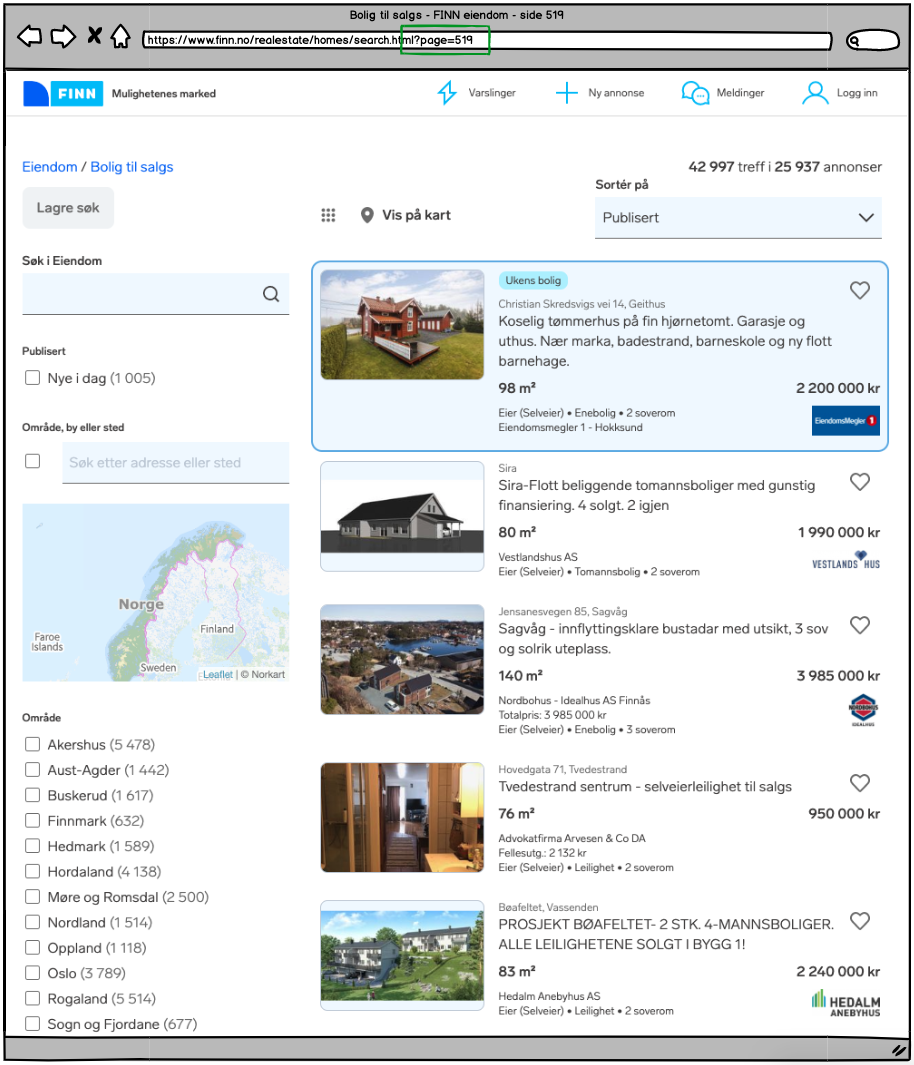
Siste side I et kategori-sett med 519 sider.
Legger vi inn neste side i URL-en — hva får vi?
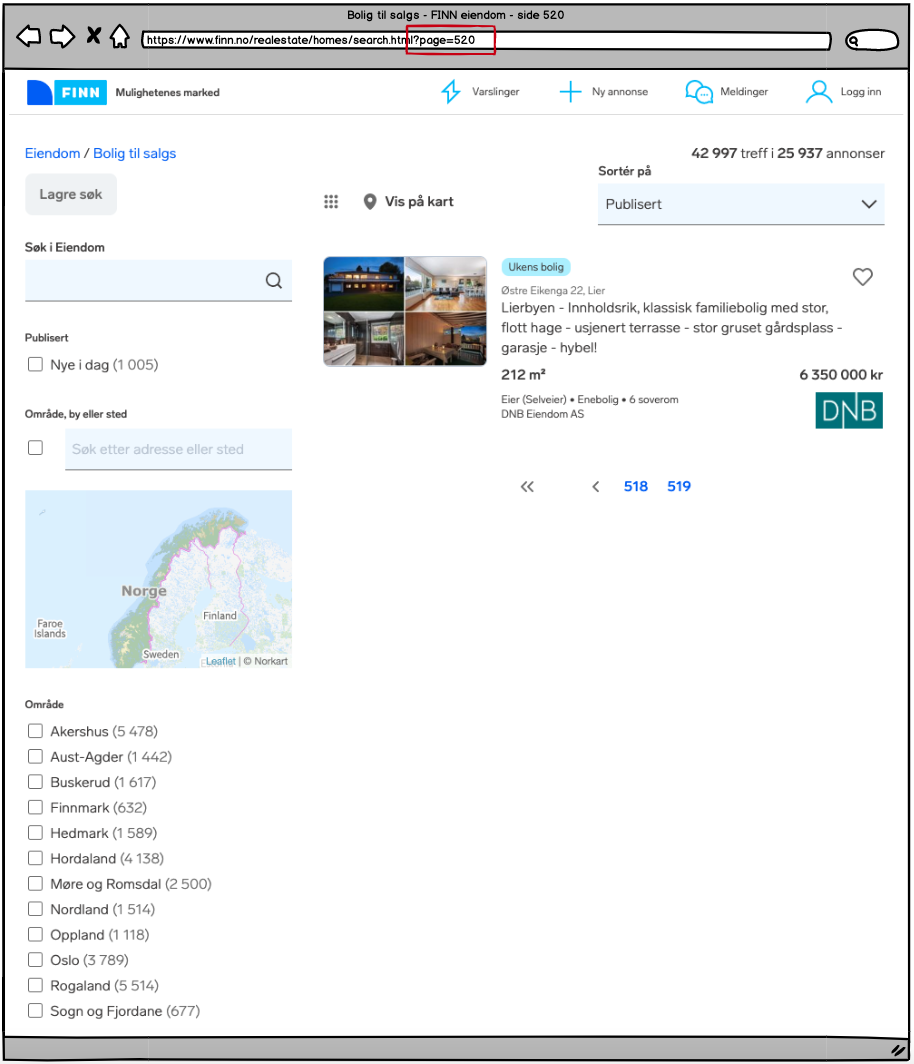
Side 520 – en tom side uten unikt innhold. Vi prøver oss med et steg til:
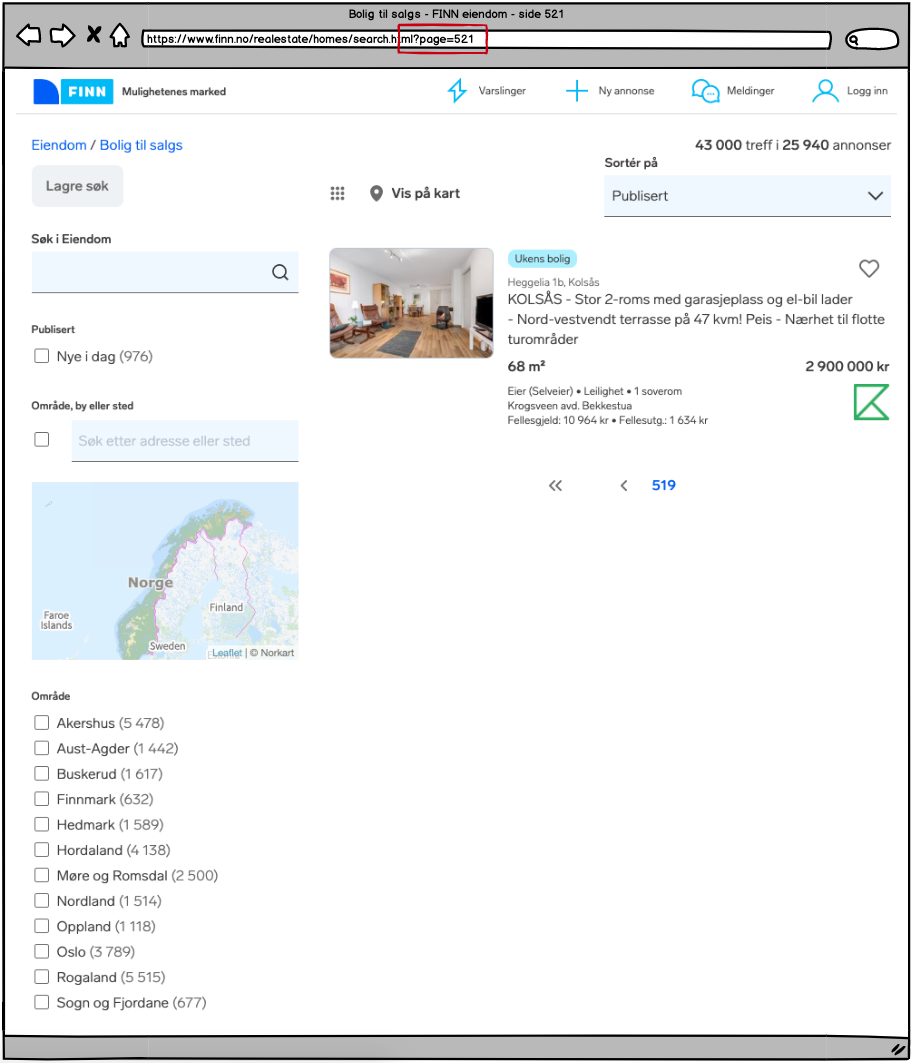
Side 521 – en kliss lik side som side 520. Og slik kan det fortsette ut i det uendelige.
Dette er en svakhet som gjør at vi helst unngår bruk av parameter i paginering. Det går i mange tilfeller veldig bra, og det er ikke noe problem for søk og rangering i seg selv, men farene som er nevnt er reelle, og kan skade bedriften på mange andre måter enn kun det å få sidene synlige i søkeresultater.
Går vi over til statiske URL-er er denne strukturen vanlig å se på mange nettsteder:

Et problem som kan oppstå her er at denne kan gi et brudd i strukturen. Gjør en test hvor du går på en slik adresse, deretter fjerner du siste nivå i URL-strukturen (2/). Da vil du sitte igjen med følgende URL:
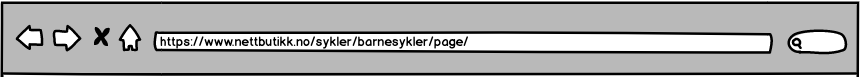
Hva får du opp? I de aller, aller fleste tilfeller en 404-side. Det sier seg selv ikke er det mest optimale for nettsiden din.
Skal du velge en statisk løsning vil jeg derfor anbefale at du kutter ned på ett nivå, slik at URL-en ser slik ut:

Det spiller dog ingen rolle om siste nivået er:
- /page-2/
- /page2/
- /page=2/
Rel=«prev» og Rel=«next»
Bruker du paginering på nettstedet ditt er det en stor sjanse for at du allerede har implementert rel=prev og rel=next. Dette gir beskjed til søkemotorer om at siden er en del av flere sider, og hvilket nummer i rekken den siden er. For eksempel om du er på side 3 av 6, så forteller rel=prev hvilken URL som er side 2, mens rel=next forteller hvilken URL som er side 4.
Dette vil ligge i <head>-tag:
- Rel=prev og rel=next vil se slik ut på nettsiden deres (på side 3):
- <link rel=»prev» href=»https://www.domene.no/kategori/side-2/»>
- <link rel=»next» href=»https://www.domene.no/kategori/side-4/»>
Google kunngjorde i 2019 at de har sluttet å bruke rel=prev og rel=next. Dette betyr ikke at at du bør slutte å bruke det. Det vil fortsatt være til hjelp for andre crawlere, og vi bør alltid gi crawlere mest mulig hjelp til å forstå nettstedet ditt. Disse lenkene guider crawlerene videre ned i strukturen, så det anbefales fortsatt å ha implementert på nettstedet i kombinasjon med paginering av sider.
Paginering og canonical tag
Vi må vite hvordan vi kombinerer paginering med canonical tag. Det er to forskjellige løsninger vi går gjennom:
Dersom du har en view all-side:
Har du flere paginerte sider, men også en view all-side (vis alle/alt), så skal canonical tag:
- Oppgi view all-siden på alle delsidene.
- På side 1, 2, 3, etc: <link rel=»canonical» href=»https://www.domene.no/kategori/view-all/»>
- Oppgi seg selv på view all-siden.
- På view all-siden: <link rel=»canonical» href=»https://www.domene.no/kategori/view-all/»>
Dersom du ikke har en view all-side:
En feil mange gjør er at alle delsidene (Side 1, 2, 3, 4, etc.) oppgir side 1 som canonical. Dette er feil bruk av canonical tag. Det man derimot bør gjøre er følgende:
- Side 1: <link rel=»canonical» href=»https://www.domene.no/kategori/»>
- Grunnen til at jeg ikke har https://www.domene.no/kategori/side-1/ er at første siden skal ha en clean URL uten sidenummer.
- Side 2: <link rel=»canonical» href=»https://www.domene.no/kategori/side-2/»>
- Alle delsidene skal oppgi seg selv i canonical.
- Side 3: <link rel=»canonical» href=»https://www.domene.no/kategori/side-3/»>
- Alle delsidene skal oppgi seg selv i canonical.
- etc.
Dynamiske URL-er i XML Sitemaps?
XML sitemaps skal som fingerregel alltid kun inneholde sider man ønsker indeksert, og som returnerer statuskode 200 til klienten som etterspør siden. Dynamiske URL-er man ikke ønsker indeksert skal derfor ikke inkluderes i XML sitemap.
Bonus tips: XML-sitemaps bør organiseres må en måte hvor du separer sidetyper i hver sin separate sitemap-fil. Dette gjør det enklere å monitorere for feil på templates. Noe som gir mulighet for svært effektive tiltak som også kan være raske å implementere.
Hva gjør vi så med interne søkeresultatsider?
Har du en søkefunksjon på nettstedet ditt oppretter denne like mange nettsider som søk blir gjennomført. Denne vil opprette adresser noe liknende dette: https://www.domene.no/search?q=søkeord/
Foruten at dette koster crawlcost har Google ytret at de ikke er veldig begeistret for å sende brukere til interne søkeresultater. Dette er sett på som dårlig brukeropplevelse med lav verdi for brukere. Derfor bør vi ta noen forhåndsregler når det kommer til interne søkeresultatsider.
Dette kan enkelt unngås ved å implementere <meta name=»robots» content=»noindex,follow»> på alle disse sidene. Eksisterende og automatisk på nyopprettede. Mange CMS og plugins har dette som en integrert løsning, som for eksempel Yoast SEO som er en WordPress plugin.
Eksempel på noen som ikke har gjort dette, og får indeksert sider som kan virke negativt på domenet og bedriften:

Utklippet over viser en norsk bank som har per i dag 432 (ca) interne søkeresultater indeksert i Google. I slike tilfeller kan det være et stort sikkerhetsbrudd da man ikke har noen kontroll over hva brukere plotter inn i søkefeltet. Brukere kan misforstå, eller bare gjøre feil. Noe som kan føre til at man legger inn sensitiv informasjon eller data i søkefeltet og vipps så har Google indeksert innholdet. En klassisk brukerfeil er når input-feltet blir forvekslet med innlogging, og personnummer fylles inn.
Man er også utsatt for brukere som vil sabotere for deg. Man kan bevisst gjøre søk som man ikke vil assosieres med eller ikke har tillatelse til å gjøre kjent. Dette kan potensielt skade bedriftens omdømme.
Hvordan endre fra dynamiske URL-er til en logisk semantisk nettstedsstruktur?
Dersom du nå innser at du har en jobb å gjøre, og ønsker å opprette kategori- og underkategorisider bør du vite hvordan du håndterer dine gamle URL-er med parametere.
Mange som ikke har den nødvendige kunnskapen tror at man bare kan slette eller noindeksere de gamle sidene og opprette nye, så vil det løse seg selv.
Dette må dere ikke finne på å gjøre! Selv med dynamiske parametere vil dere over tid få bygget opp verdifulle sider som genererer trafikk og salg.
Sletter dere disse når dere oppretter de nye sidene vil all verdi og tidligere hardt arbeid være bortkastet for videre drift. Det som er viktig å tenke på når man går over fra en dynamisk URL-struktur er hvordan man får overført kunder og verdi til de nye sidene.
Man bør ta følgende grep:
- En enkelt (1-til-1) 301-redirect sørger for at brukere og boter havner på riktig destinasjon.
- Alle interne lenker i kommersielt og redaksjonelt innhold bør endres slik at de peker til den nye siden med absolutt URL.
- Sørg for at alle nye URL-er har minimum en (1) intern lenke til seg.
- Inkluder de nye URL-ene i XML-sitemaps, fjern alle gamle/non-200 URL-er og submit den/dem til Google via Google Search Console.
Viktigste takeaway
Som du skjønner er det ikke slik at man kan velge seg ut en metode og tenke at den automatisk vil passe din løsning. Dette er ikke en one size fits all. Mange tilfeller krever at man velger flere metoder som sammen løser dette mest mulig optimalt for ditt nettsted.
Skal jeg trekke ut en viktig detalj jeg ønsker du skal ha med deg videre er det dette jeg har lært av å jobbe med kollega og sjef Trond Lyngbø: URL-struktur handler mindre om selve URL-en, men om:
- arkitektur og nettstedsstruktur,
- organisering av innhold,
- navngiving av kategorier,
- med mer.
Mange har for mye fokus på hvordan URL-en for detaljsiden skal se ut. Hvor mange søkeord man kan trekke inn. Hvor lang den skal være.
Skal du lykkes med SEO i dag står det ikke på hvordan URL-en ser ut, men hvordan du bygger opp nettstedet ditt. Utvikler du et nettsted basert på analyse og ekspertise, er det her du vil gjøre den store forskjellen.
Resultat? Du vil sitte igjen med en pengemaskin fra et tidlig stadium. En selvgående selger i eliteklassen som kan skalere, og følge bedriften og markedet omsetningseffektivt i lang tid.

Om forfatteren
Jørgen Indsetviken
Hei! Takk for at du leste artikkelen jeg har skrevet, jeg håper den var til nytte. Er det noe du lurer på etter å ha lest, ta gjerne kontakt.
Kort meg: SEO-ekspert med interesse for teknisk SEO for e-handelsaktører, nettbutikker og SMB-markedet.