Hva er canonical tag?
Canonical link element er et HTML-element som ofte blir referert til som canonical tag eller rel=canonical.
Hensikten med canonical tag er å opplyse søkemotorer om hvilken av flere sider man ønsker skal indekseres og rangeres i søkeresultatsidene der hvor duplisert innhold kan være et problem.
Brukere har ingen nytte av å lese denne informasjonen, så denne ligger skjult i kildekode, response headers og/eller sitemaps, avhengig av hvordan man implementerer løsningen.
Arbeider man strategisk med SEO burde man sette seg inn i hvordan man håndterer duplisert innhold da dette kan ha negativ påvirkning på virksomhetens organiske synlighet, og derfor virksomhetens finansielle tall.
Hvordan fungerer det – og hvorfor er det viktig for SEO?
Canonical tag skal bidra til at man får optimal flyt av verdi til – og effektiv målretting av korrekt versjon av sider med duplisert innhold.
Søkemotorer som Google liker ikke nettsteder som publiserer duplisert innhold uten å merke det for nettopp det. Grunnen til dette er at søkemotorer ønsker å servere de sidene de mener er best egnet for å løse brukerens forespørsel basert på intensjon.
Finnes det ti sider med det samme innholdet har ikke Google nytte av å rangere disse ti sidene med samme innhold på samme søkeresultatside, og vil derfor plukke ut kun en. Uten korrekt merking av versjonenes forhold til hverandre er Google nødt til å selv finne ut hvilken den tror er originalen/den foretrukne.
Vi etterlater da ansvaret til Google, og resultatet er redusert kontroll, og økt risiko for at kjøpsklare kunder og verdifull trafikk går til konkurrerende nettsteder, eller blir servert en underoptimalisert side som har redusert CTR i SERP-en og en lavere konverteringsfrekvens.
For å få et renere søkeresultat innførte Google i 2011 The Panda Update. Denne oppdateringen har som hensikt å oppdage duplisert innhold og deretter filtrere dette bort.
Mange tror at Panda kan gi et nettsted en penalty, altså at Google direkte straffer nettstedet. Enten hele eller på sidebasis. Dette er feil. Panda gir ingen penalty, kun filtrerer bort på enkeltsider. Dette er en stor forskjell.
Der hvor en penalty kan gi nettstedet en prikk på det uttømmende rullebladet, og krever mer omfattende tiltak å rette opp i, vil filtreringen kun kreve at innholdet endres såpass mye at Panda ikke utløses, eller at man merker det korrekt med en canonical tag.
Man må allikevel ta innover seg at dersom du har mye duplisert innhold, kan resten av nettstedet få en negativ påvirkning. Strategiske SEO-tiltak og effektiv innholdsmarkedsføring er derfor essensielt for å utvikle og vedlikeholde et sikkert nettsted av høy kvalitet.
Implementering
Så hvordan implementerer man rel=canonical?
Det kan gjøres via flere måter, men de mest vanlige er følgende:
- HTML Head-tag
- For nettsider (HTML-dokument)
- HTTP Header
- For andre filer som f.eks. PDF
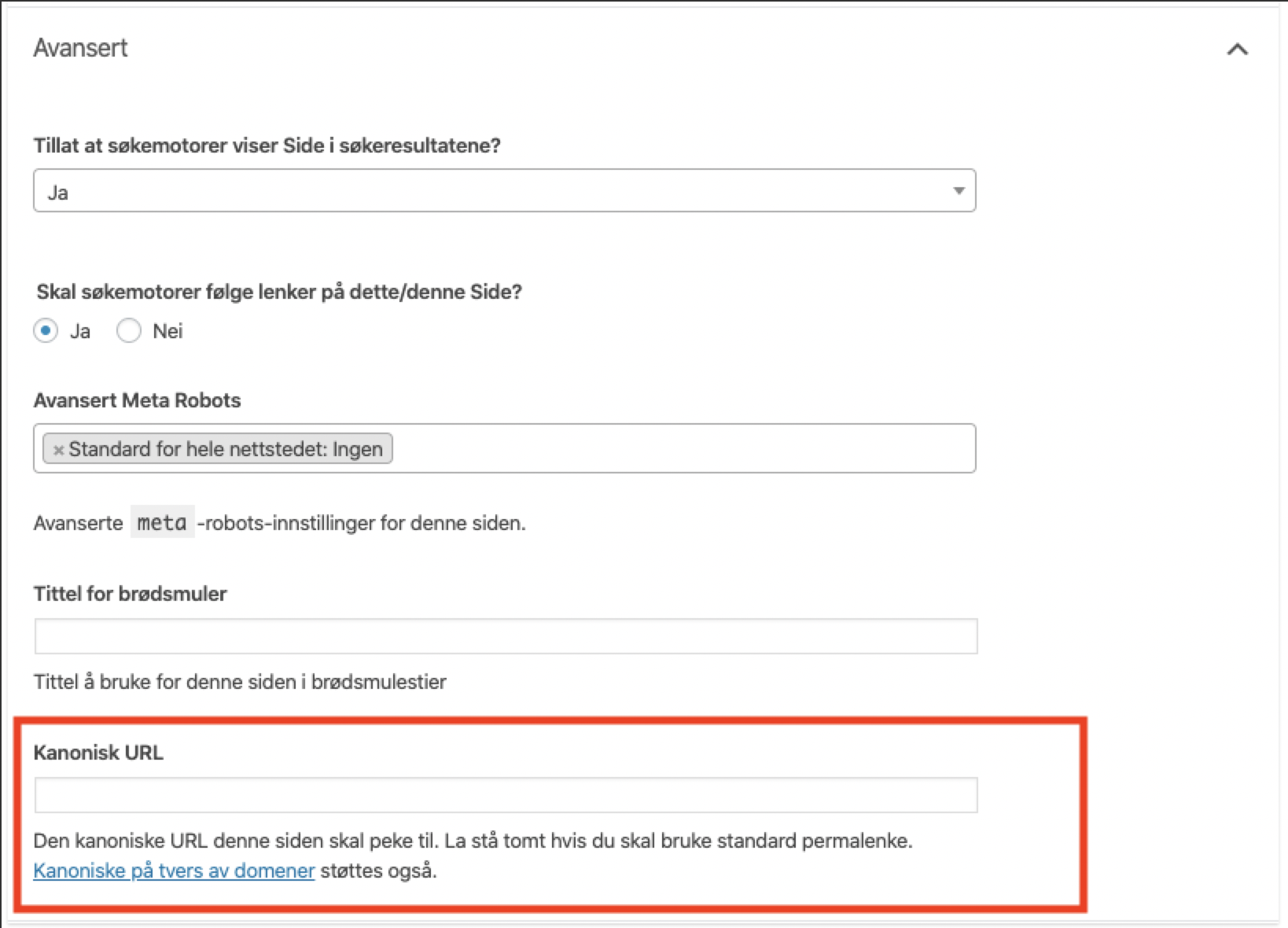
HTML Head-tag
Nettsider bør implementere rel=canonical i Head-tag I HTML-dokumentet.
Canonical link element ser slik ut:
<link rel=»canonical» href=»https://www.domene.no/kategori/underkategori/detalj-side/»>
For å legge inn dette er det flere metoder man kan bruke. Har du en utvikler vil denne hjelpe deg med dette.
Har du f.eks. WordPress så har Yoast SEO et eget felt for enkel innfylling av canonical URL.
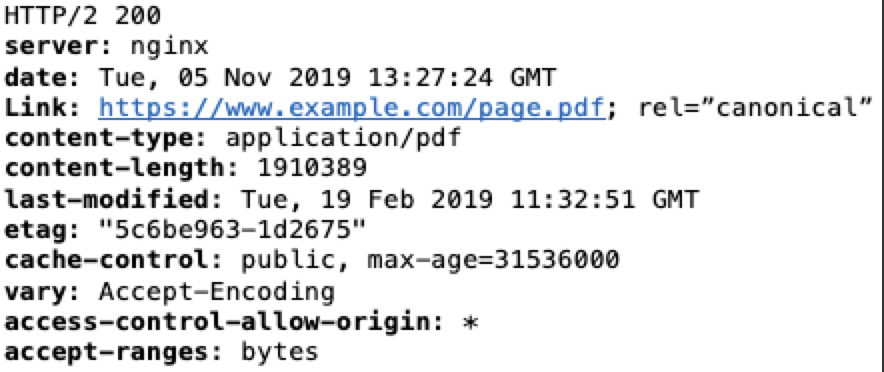
HTTP Header
For filer og andre elementer på nettstedet kan man oppgi canonical via HTTP Header.
Canonical link element I HTTP Header ser slik ut:
Canonical tag er kun et hint
Rel=canonical blir behandlet av Google som et hint, ikke et direktiv. Det betyr at Google ikke nødvendigvis alltid følger implementeringen.
Grunner som:
- manglende canonical tags,
- flere tilfeller på samme side,
- self-referencing canonical tag på flere dupliserte sider,
- alle tags peker mot samme side,
- med fler
kan forårsake at Google velger å ignorere implementeringen. Da sitter vi igjen med bortkastet tid og kostnader fra implementeringen, i tillegg til tapte muligheter fra tiltakene som implementeringen i utgangspunktet skulle sørge for.
På bakgrunn av dette skal man være nøye med hvilke problemstillinger man prøver å løse med denne taggen.
Hva løser en canonical tag?
Rel=canonical er utviklet i den hensikt å fortelle søkemotorer om hvilken av flere versjoner av samme innhold er den ene du ønsker å indeksere og rangere.
Nettopp fordi Google kan velge å ignorere taggen ved tilfeller av feil, må man derfor har tungen beint i munn når man implementerer elementet.
Tilfeller som canonical tag kan løse dersom Google velger å følge elementet:
- Dupliserte versjoner ved f.eks. tracking parameter
- Dynamiske URL-er hvor Canonical tag kan bli brukt i istedenfor noindex kan bruke Canonical tag som oppgir URL-en uten parameter
- Eksempel:
- Side: https://www.domene.no/side/?trackingid=123
- Kode: <link rel=«canonical» href=»https://www.domene.no/side/» />
- Kryss-publisering av innhold på eget domene
- Spesielt i nettbutikker kan kryss-publisering være et problem. Produkter som hører hjemme i – og ligger i flere kategorier i URL-strukturen har behov for rel=canonical
- Kryss-publisering av innhold på tvers av domener
- Artikler og annet innhold som publiseres på eget domene, men også hos partnere, tabloider, etc. bør markeres med rel=canonical pekende mot ditt nettsted. Dette hindrer at andre domener bli rangert høyere enn deg som er original, og derfor mottar dyrebar trafikk som egentlig du har fortjent
- Ved paginering
- Dersom du har en View all-side skal alle rel=canonicals på komponentsidene peke mot denne
- Dersom du ikke har en View all-side skal alle komponentsidene ha en self-referencing rel=canonical
- Ved A/B testing
- Er innholdet likt, men man tester endringer på f.eks. design
- Print
- Dersom du har en print versjon av en side på egen URL skal denne inneholde rel=canonical pekende mot original side
Hva løser ikke canonical tag?
Mange mistolker hensikten til canonical link elementet. Som nevnt skal canonical tag brukes når man ønsker at flere versjoner av samme innhold fortsatt skal være tilgjengelig for brukere.
Et kjent feilgrep er når man forveksler canonical tag med en 301-redirect.
Tilfeller som canonical tag ikke løser, men derimot en 301-redirect bør velges:
- Protokoll-duplikat
- Har du nettstedet både på HTTP og HTTPS skal man bruke 301-redirect mot den foretrukne. Som i dette tilfellet vil være HTTPS
- WWW vs. non-WWW
- Det har ingen påvirkning i forbindelse med SEO om du bruker WWW eller ikke, så lenge du holder deg til en versjon
- Sørg for å ha en 301-redirect mot den versjonen du velger
- Sørg for at alle interne lenker (inkludert canonical tags) peker mot riktig versjon
- Trailing slash «/»
- En trailing slash indikerte tidligere at gjeldene adresse var en folder. Dette er ikke tilfellet i dag. Det har ingen betydning om du velger å bruke trailing slash eller ikke. Altså en «/» på slutten av URL-en.
- Sørg for å velge en versjon, og hold deg til den
- 301-redirect til den valgte versjonen
- Sørg for at alle interne lenker (inkludert canonical tags) peker mot riktig versjon
- Duplikat hjemmeside
- Finnes hjemmesiden på flere adresser som f.eks.:
- https://www.domene.no/
- https://www.domene.no/home.html
- https://www.domene.no/index.html
- Sørg for en 301-redirect mot en versjon
- Gamle, utdaterte sider hvor det er kommet en «arvtager»
- Har du laget en ny versjon av f.eks. en gammel artikkel kan det i tilfeller være hensiktsmessig med en 301-redirect fra den gamle til den nye, slik at man ikke målretter de samme søkeordene
- Upper og lowercase URL-er
- Dersom løsninger din tillater adresser med store og små bokstaver bør du ha en 301-redirect til kun lowercase URL-er
Canonical tag og Hreflang – Internasjonal SEO
Hreflang kan på mange måter sammenlignes med canonical tag. Der hvor rel=canonical oppgir duplisert innhold på samme språk, skal hreflang indikere forskjellige språkversjoner av samme innhold.
Hreflang fungerer, og skal brukes på språkversjoner fordelt på ccTLD, subdomener og subfoldere.
Eksempler ccTLD, subdomener og subfoldere:
- ccTLD
- https://www.domene.no/side/
- https://www.domene.se/sida/
- Subdomene
- https://www.no.domene.com/side/
- https://www.se.domene.com/sida/
- Subfolder
- https://www.domene.com/no/side/
- https://www.domene.com/se/sida/
På lik linje som rel=canonical blir også hreflang tolket som et hint av Google, og krever derfor en nøye implementering for at det skal virke optimalt. Hreflang har dog ingen påvirkning på verken duplisert innhold eller rangering. Hensikten til hreflang er at brukere skal få servert den mest relevante versjonen i sitt søkeresultat.
Sitter du i Norge er det lite brukervennlig å få servert den svenske versjonen, dersom det finnes en norsk versjon.
Eksempel
- La oss si at du har en nettbutikk som selger sportsutstyr i både Norge og Sverige med følgende ccTLD:
- https://www.sportsutstyr.no/snowboard/burton-genie/
- https://www.sportutrustning.se/snowboard/burton-genie/
*Eksempelet viser en side for et snowboard av merket Burton og modell Genie.
Innholdet på disse to sidene er i stor grad likt, men tilpasset målgruppene i aktuel region.
Vi er ønsker derfor å fortelle til Google hvilken relasjon disse sidene har til hverandre.
Hreflang har mulighet til å indikere både språk og region.
Eksempel
- nb-no er kode for norsk bokmål i Norge
- se-se er kode for svensk språk i Sverige
- se-no er kode for svensk språk i Norge
Hreflang implementeres på samme måte som rel=canonical i HTML Head-taggen eller i HTTP headeren.
For nevnte eksempel-sider ønsker vi derfor å indikere forholdene i HTML Head-taggen slik:
- https://www.sportsutstyr.no/snowboard/burton-genie/
- <link rel=»alternate» href=»https://www.sportsutstyr.no/snowboard/burton-genie/» hreflang=»nb-no» />
- <link rel=»alternate» href=»https://www.sportutrustning.se/snowboard/burton-genie/» hreflang=»sv-se» />
- https://www.sportutrustning.se/snowboard/burton-genie/
- <link rel=»alternate» href=»https://www.sportsutstyr.no/snowboard/burton-genie/» hreflang=»nb-no» />
- <link rel=»alternate» href=»https://www.sportutrustning.se/snowboard/burton-genie/» hreflang=»sv-se» />
La du merke til noe?
Begge adressene oppgir også seg selv. Dette er viktig for at Google skal forstå den gjeldende sidens relevans i forbindelse med de(n) andre siden(e) som oppgis.
Så – hvordan kombinerer vi dette med rel=canonical?
Det er enkelt, men allikevel ikke så enkelt skal det vise seg.
På hver av de aktuelle adressene som oppgis i hreflang-tags så skal sidene være self-referencing i sin canonical tag.
Det vil si at sidenes Head-tag vil se slik ut:
- https://www.sportsutstyr.no/snowboard/burton-genie/
- <link rel=»canonical» href=»https://www.sportsutstyr.no/snowboard/burton-genie/» />
- <link rel=»alternate» href=»https://www.sportsutstyr.no/snowboard/burton-genie/» hreflang=»nb-no» />
- <link rel=»alternate» href=»https://www.sportutrustning.se/snowboard/burton-genie/» hreflang=»sv-se» />
- https://www.sportutrustning.se/snowboard/burton-genie/
- <link rel=»canonical» href=»https://www.sportutrustning.se/snowboard/burton-genie/» />
- <link rel=»alternate» href=»https://www.sportsutstyr.no/snowboard/burton-genie/» hreflang=»nb-no» />
- <link rel=»alternate» href=»https://www.sportutrustning.se/snowboard/burton-genie/» hreflang=»sv-se» />
Vanligste feil med hreflang i kombinasjon med rel=canonical
- Hreflang oppgir en non-indexable URL
- Hreflang skal alltid oppgi URL-er som er self-referencing i sin canonical tag
- Feil implementering av canonical tag har derfor en negativ ringvirkning på hreflang og internasjonal SEO. Dette kan negativt påvirke trafikk og salg i ikke bare ett land, men i alle landene du er representert i!
- Hreflang er implementert på non-indexable URL-er
- I likhet med punktet over skal heller ikke sider som ikke er indekserbare har implementert hreflang-tags
- Det vil si: dersom du har en side med en canonical tag som peker mot en annen side, skal denne altså ikke ha hreflang implementert
Det er flere vanlige feil relatert til hreflang, men i dette innlegget vil jeg fokusere på hreflang i kombinasjon med rel=canonical.
*Ønsker du å opprette hreflang-tags for ditt nettsted er denne Hreflang generatoren laget av Aleyda Solis å anbefale.
Hvordan gjøre en audit av canonical?
Etter å ha lest deg ned til dette punktet, har du forhåpentligvis forstått viktigheten av korrekt implementering.
Har du implementert rel=canonical bør du jevnlig gjennomføre en liten helsesjekk på nettstedet ditt. Ta en audit med fokus på forskjellige elementer hvor canonical link element er et element.
Her er en liste over vanlige feil du burde se etter, og rette opp i så fort som mulig:
- Canonical chains
- Implementering av Canonical tags skal i likhet med redirects ikke inneholde chains (kjede)
- En Canonical chain vil si å være følgende:
- Side A oppgir side B som Canonical
- Side B oppgir side C som Canonical
- Side C oppgir seg selv som Canonical
- Feilen her? Side A skulle også oppgitt side C som Canonical
- Flere tilfeller av Canonical på samme side
- Sider som oppgir flere Canonicals på samme side forvirrer Google. Google får ingen tydelig indikator på hvilken som skal regnes som den foretrukne versjonen, og Google vil mest sannsynlig velge på egenhånd
- For ulikt innhold mellom side A og side B
- Canonical taggens hensikt er å plukke ut en versjon av flere duplikater. Er det ikke duplikater, eller at sidene er for ulike vil Google velge å se på det som to forskjellige sider, og derfor ignorere implementeringen
- Interne lenker peker ikke mot Canonical-versjon
- For optimal effekt av interne (og eksterne) lenker bør man oppgi versjonen man ønsker å indeksere og rangere i lenker så brukere og søkemotorer kommer direkte til ønsket destinasjon
- Blandet Noindex og canonical
- Blander du noindex og rel=canonical på samme side kan det oppstå problemer
- Side A oppgir side B som Canonical
- Side B oppgir seg selv som Canonical
- Alt er så langt bra
- Dersom det blir lagt på noindex på side A blir denne fjernet fra, eller havner aldri i indeksen
- Google kan velge å tolke det som at side B også skal være noindex, og side B blir også fjernet fra, eller havner aldri i indeksen
- Peker mot feil versjon (www vs. non-www og http vs. https).
- Er nettstedet basert på www skal alltid www oppgis i rel=canonical
- Er nettstedet basert på https skal alltid https oppgis i rel=canonical
- Bruker nettstedet trailing slash skal alltid trailing slash oppgis i rel=canonical
- Peker mot 3xx, 4xx, 5xx adresser
- Sørg for at alle sider som ligger i en Canonical tag er en valid adresse
- Kun sider/URL-er som responderer med statuskode 200 skal brukes i forbindelse med implementeringen
- Blandet uppercase og lowercase tegn
- Sørg for at alle oppgitte URL-er er identisk til den du ønsker skal indekseres og rangeres
- Har du en 301-redirect av uppercase til lowercase bokstaver må du allikevel oppgi korrekt adresse i implementeringen
- Oppgir man en adresse som krever ett eller flere steg for å komme til destinasjonen, øker man sjansen for at Google ignorerer implementeringen
- Bruker relative URL-er
- Absolutt URL: https://www.domene.no/kategori/artikkel/
- Relativ URL: /kategori/artikkel/
- Sørg for å alltid oppgi absolutte URL-er
- Alle canonicals peker mot samme side
- Alle rel=canonicals peker mot hjemmesiden
- Det hender vi kommer over tilfeller hvor Canonical tag er implementert hvor alle peker mot hjemmesiden, eller en annen side
- Ved paginering
- Dersom du har paginering, altså en katalog e.l. som er delt opp i flere sider som side 1, side 2, side 3, etc. Opplever vi ofte tilfeller hvor rel=canonical på alle sidene peker mot side 1
- Som nevnt tidligere:
- Dersom du har en view all-side skal alle komponentsidene oppgi denne i rel=canonical
- Dersom du ikke har en view all-side skal alle komponentsidene være self-referencing
- Ligger i JavaScript
- Google og andre søkemotorer render og leser ikke alltid innhold som ligger i JavaScript umiddelbart. Dette kan forårsake at tags som skal ligge i header ikke er tilgjengelige når de skal
- Ligger i <body>
- For at implementeringen skal være gyldig – pass på at den ikke ligger i <body>, men i <head>
- Ligger etter en iframe
- Har man en <iframe> i Head-taggen kan dette forårsake at crawlere lukker Head-taggen, og kode etter dette vil ikke være tilgjengelig
- Sørg for at iframes kommer til slutt i Head-taggen
- Inkluderer non-indexable canonicalized URLs I sitemap
- XML sitemap skal kun inkludere valide 200-sider
- Sørg for at sider som har en rel=canonical pekende bort fra gjeldende side ikke inkluderes i XML sitemap
- Gode verktøy
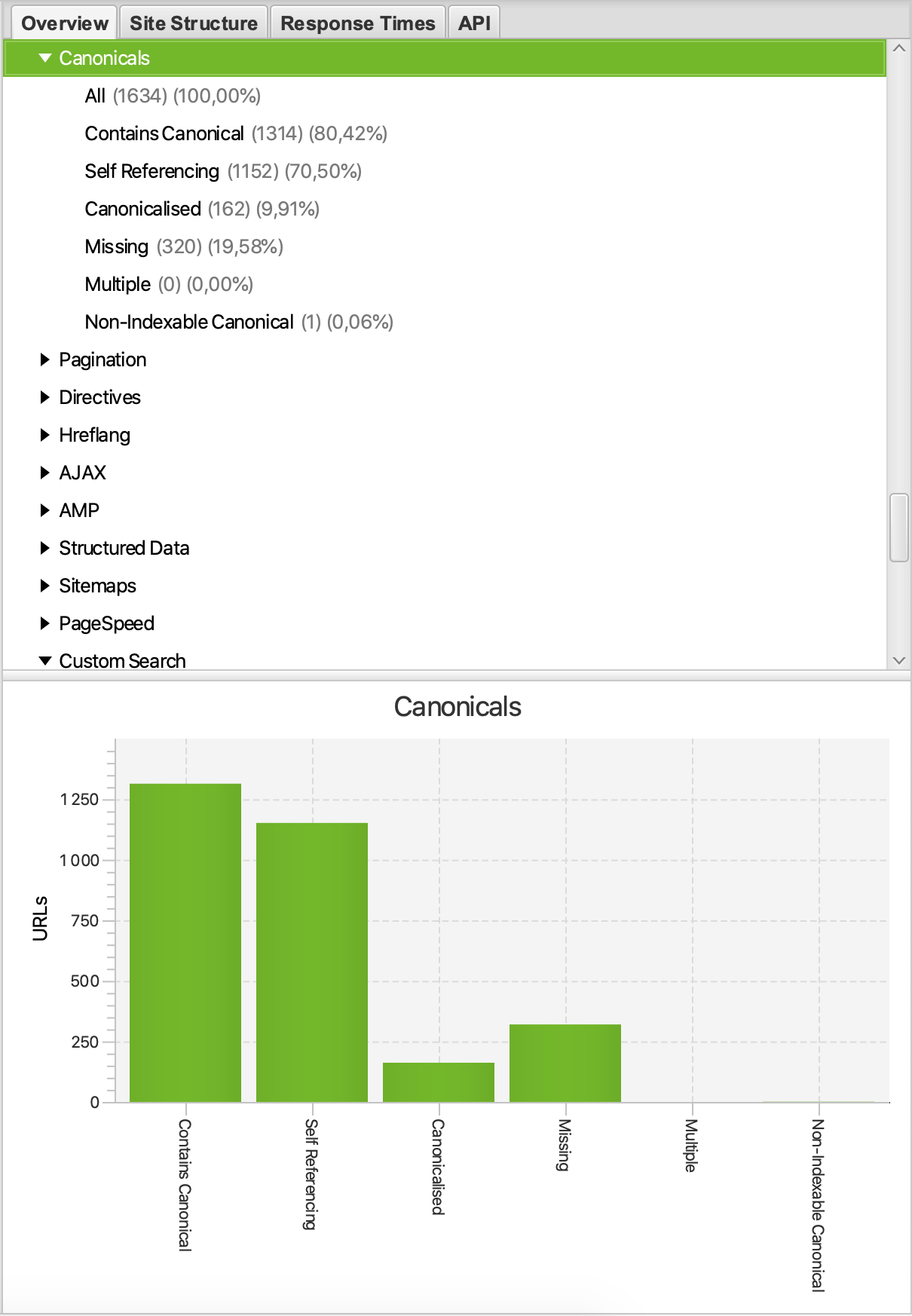
- Screaming Frog SEO Spider
- Screaming Frog SEO Spider er et verktøy som på lik linje med Google crawler nettsteder, og ekstrakter informasjon. Programmet lastes ned og ligger lokalt på maskinen din.
- SEO Spider har en egen fane for rel=canonical hvor en god del feil blir presentert. Her kan må se blant annet:
- Manglende canonicals
- Flere canonicals på samme side
- Adresser som ikke kan indekseres, men er oppgitt som foretrukket versjon
- Canonical chains
- Her kan dere se et utdrag fra programmet med en oversikt over noen av de nevnte punktene:
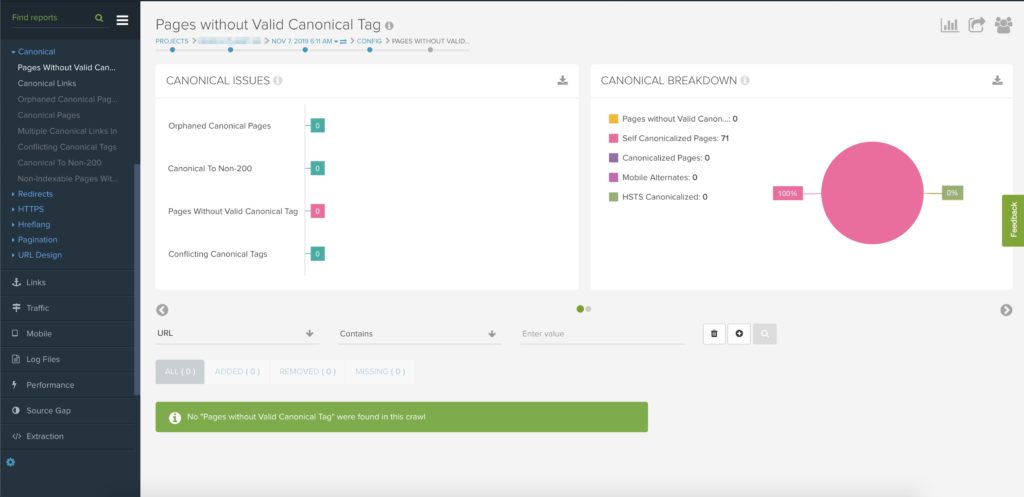
- Deepcrawl
- Deepcrawl fungerer på mange måter som Screaming Frog SEO Spider, men istedenfor å være et lokalt verktøy, er dette en internettjeneste. Altså vil ikke crawlingen kreve noe av maskinen din, og crawlingen kan foregå uten at du har maskinen påslått.
- Slik ser brukergrensesnittet ut i Deepcrawl. I listen til venstre ser man et utdrag av elementer som trigger advarsler og feil i forbindelse med rel=canonical:
Tips: Blir en non-canonical versjon indeksert tyder det på at Google ignorerer canonical taggene dine. Dette er en indikator på at du har en eller flere feil med implementeringen, og en SEO audit kreves for å finne og rette opp i feil.
Hva gjør vi dersom vi skal kvitte oss med duplikate sider?
Generelt skal man passe litt på når man skal fjerne sider fra nettstedet. Det er ikke alltid bare å slette sider man tror en ikke har bruk for, og servere en 404 helt uten videre.
Grunnen til dette er at selv om en side er duplikat, og man tror den kanskje ikke har mye nytte av seg på grunn av lav trafikk, kan den fortsatt ha andre egenskaper som er svært viktige.
For eksempel burde man bruke analysedata for å se hvordan trafikken flyter videre fra den siden. Det kan hende at siden har en lavt volum med brukere fra organisk søk, men at trafikken som kommer inn er verdifull trafikk som ofte går videre inn på andre viktige sider, og sider som har høy konverteringsfrekvens.
Et annet eksempel er at selv om sider har lav trafikk så skaper den relevans til, og bygger opp andre sider. Har du i tillegg en god nettstedsstruktur og intern lenkebygging kan sider med lite trafikk ha direkte positiv påvirkning på andre sider.
Er den duplikate siden en slik type side så må du ha en løsning for hvordan du håndterer denne trafikken, før du fjerner den. Dette kan være sider med parametre basert på sortering, filtrering, etc, eller om det er sider basert på en tag-struktur.
Man bør i så tilfelle sørge for å følge rådene som fremkommer i dette innlegget i tillegg til tipsene jeg deler i dette innlegget om dynamiske URL-er.
Har du et nettsted basert på tag-struktur istedenfor, eller i kombinasjon med kategori-basert struktur, kan trafikken inn til tag-sidene være kritiske for bedriften, og ved å slette disse uten å håndtere de korrekt kan være en spiker i kista. Ikke bare for deg, men for alle ansatte i bedriften.
Eksempel
- Tag-struktur
- https://www.domene.no/tag/sofa/
- Kategori-basert struktur
- https://www.domene.no/mobler/sofa/
Jeg løser mange av problemene i det nevnte innlegget om dynamiske URL-er, men når det gjelder tag-strukturen bør dette håndteres med kategorier og redirects. Sørg for å ha en logisk semantisk URL-struktur basert på kategorisering av viktige tema og innhold. Deretter bør man se hvilke tag-sider som skaper trafikk og engasjement, og redirecte disse sidene mot de ny-opprettede eller gamle kategorisidene.
Man opplever ofte at tag-sider rangerer høyere enn kategorisidene. Da må man sørge for at kategorisidene er optimalisert med blant annet innhold og intern lenkebygging.
Hvordan håndterer vi sider som målretter det samme søkeordet?
La oss si at du har over tid publisert to, eller fler artikler som målretter de(t) samme søkeordene. Dette kan føre til kannibalisering. Altså at innholdet konkurrerer med seg selv, og du risikerer at en versjon med lavere CTR og konverteringsfrekvens rangerer over den foretrukne.
Artiklene er ikke like nok til at en rel=canonical er passende. Det vi da kan gjøre er følgende:
- Slå sammen sidene
- Oppdater den siden som rangerer best med innhold fra begge artikler
- 301-redirect gammel URL til den nye
- Oppdater alle interne lenker som peker mot den gamle adressen til å peke mot den nye
- Du kan også forhøre deg om de eksterne nettsidene som lenker til den gamle URL-en er interessert i å oppdatere til den nye
- Tips: gi dem en grunn til å gjøre det. F.eks. Kan den den nye siden med det oppdaterte innholdet være til større nytte for deres lesere
På generell basis: Vær påpasselig med å slette sider om du ikke har en «arvtager».

Om forfatteren
Jørgen Indsetviken
Hei! Takk for at du leste artikkelen jeg har skrevet, jeg håper den var til nytte. Er det noe du lurer på etter å ha lest, ta gjerne kontakt.
Kort meg: SEO-ekspert med interesse for teknisk SEO for e-handelsaktører, nettbutikker og SMB-markedet.